Part 4 - PgBouncer to ProxySQL: Extended and Prepared Protocols

Picture a normal PostgreSQL request path. The driver parses a statement, binds parameters, executes it, and then often comes back for the same statement again. That is the traffic pattern that matters in production, because it is the one that decides whether a proxy stays invisible or becomes the bottleneck.
Part 3 answered the simple-mode question. Part 4 asks the one that feels closer to real life: if we switch to PostgreSQL’s extended and prepared query paths, does ProxySQL still hold up against PgBouncer?
Using the same hardware, backend pool, and pgbench workload as Part 3, the answer is yes. ProxySQL stays ahead in both -M extended and -M prepared, and the gap widens as it uses more CPU inside a single instance.
TL;DR ProxySQL stays ahead in both extended and prepared mode. With
2workers it delivers1.30xto1.71xPgBouncer; with4workers it reaches1.53xto2.30x.
For one of the optimizations behind ProxySQL’s prepared-mode numbers, read how the prepared statement cache refactor improved ProxySQL performance.
This post closes the loop from Part 1: Rethinking the PostgreSQL Middle Tier, Part 2: A Brief Feature Comparison, and Part 3: Simple-Mode Benchmark.
Benchmark setup
Nothing changed except the protocol. Hardware, TLS, backend pool size, and workload stay fixed so we can see what PostgreSQL’s extended and prepared paths do on their own.
| Item | Value |
|---|---|
| Hardware | AMD Ryzen 9 5950X, 32 vCPU threads, 125 GiB RAM |
| PostgreSQL | 17.10 |
| PgBouncer | 1.25.1 |
| pgbench | 18.3 |
| ProxySQL | pre-release of 3.0.9 |
| TLS | Enabled on every hop: client -> pooler -> PostgreSQL |
| Workload | SELECT * FROM pgbench_accounts WHERE aid = $1 returning a 4 KB result set |
| Backend pool | 50 connections for both PgBouncer and ProxySQL |
| PgBouncer setup | pool_mode = transaction, max_prepared_statements = 256 |
| Clients | 1, 50, 100, 500, 1000 |
| ProxySQL workers | 1, 2, 4 |
| Timing | 20 s warmup, 60 s measured run |
| Reporting | 3 iterations per cell, reported as 3-run averages |
If you want the full configuration and harness details, they are the same as Part 3. This post focuses on the protocol change: simple text versus PostgreSQL’s extended and prepared paths.
The first chart
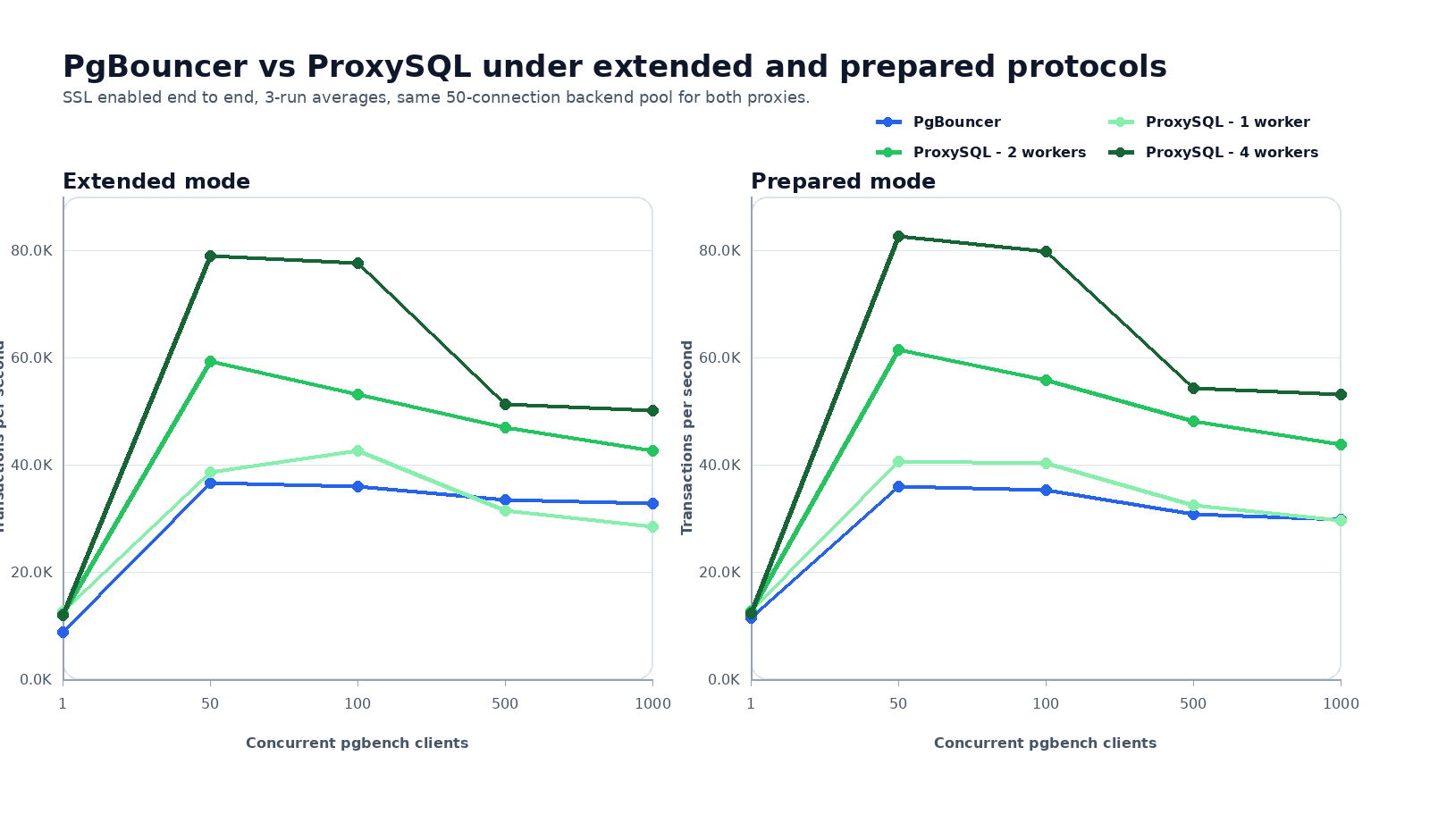
The shape is easy to read. At one client, the poolers sit close together. There is not enough pressure yet for the proxy design to matter much.
At c=50 and c=100, the path starts to separate. ProxySQL with one worker already stays competitive, and two or four workers start turning CPU into more throughput.
By c=500 and c=1000, the backend pool is fully saturated. At that point the proxy is mostly managing queues, and ProxySQL’s multi-threaded design keeps moving more requests per second than a single-threaded process.
Extended mode
The raw numbers below show the same pattern in extended mode.
c=1 | c=50 | c=100 | c=500 | c=1000 | |
|---|---|---|---|---|---|
| PgBouncer | 8.8K | 36.5K | 35.9K | 33.4K | 32.7K |
| ProxySQL 1 worker | 12.6K | 38.5K | 42.6K | 31.5K | 28.4K |
| ProxySQL 2 workers | 12.2K | 59.3K | 53.1K | 46.8K | 42.6K |
| ProxySQL 4 workers | 11.9K | 78.9K | 77.6K | 51.3K | 50.1K |
Prepared mode
Prepared mode tells the same story again, but it is a little more interesting because it leans harder on ProxySQL’s PostgreSQL prepared-statement work.
c=1 | c=50 | c=100 | c=500 | c=1000 | |
|---|---|---|---|---|---|
| PgBouncer | 11.4K | 35.9K | 35.2K | 30.8K | 29.7K |
| ProxySQL 1 worker | 12.8K | 40.6K | 40.2K | 32.5K | 29.5K |
| ProxySQL 2 workers | 12.5K | 61.4K | 55.8K | 48.0K | 43.8K |
| ProxySQL 4 workers | 12.3K | 82.5K | 79.7K | 54.3K | 53.2K |
The heatmap below makes the same point another way. PgBouncer is the 1.00x baseline in every column.
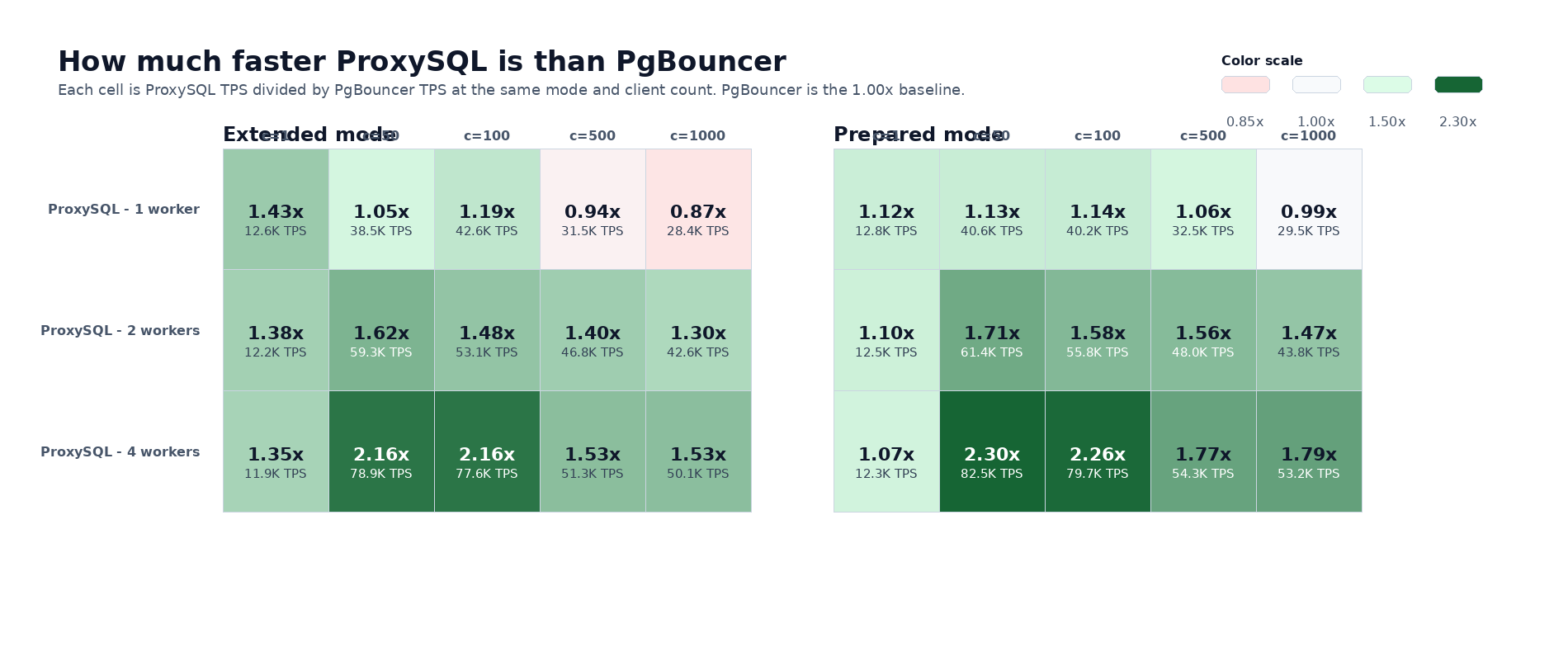
The important part is not the exact color in any one cell. It is the pattern: one worker stays close, two workers pull ahead, four workers widen the gap. That holds in both extended and prepared mode.
Why ProxySQL wins here
Part 2 showed the functional side of the story: ProxySQL keeps routing, monitoring, and query policy in the proxy itself. Part 4 shows the performance side: it can do that while staying competitive on the protocols PostgreSQL applications actually use.
PgBouncer is intentionally lean and single-threaded per process. That is good when you only need pooling. ProxySQL is built to do more at the proxy layer: parse PostgreSQL traffic, apply query rules, track backend role and lag, and keep those decisions inside a single operational surface.
The benchmark numbers show that this extra capability is not paid for with a throughput penalty on these workloads. In simple terms, ProxySQL is not just the more capable proxy here. It is also the one that turns more CPU into more throughput when the proxy becomes the bottleneck.
What this means in practice
If your applications use PostgreSQL’s extended or prepared protocol, ProxySQL still looks like the better choice. It keeps more policy in the proxy, and on this workload it turns that into throughput rather than overhead. With two workers the gain is already substantial; with four workers the gap is obvious.
Bottom line
Part 4 strengthens the answer from Part 3 instead of softening it. Once the protocol matches how PostgreSQL applications actually behave, ProxySQL still leads, and the lead grows as you give it more worker threads.
That is the real takeaway from Part 4: moving from PgBouncer to ProxySQL is not a trade between capability and speed. In this benchmark, ProxySQL gives you the more capable proxy and, in most of the meaningful concurrency range, more throughput too.