Scaling from a Dark Ages of Big Data to Brighter Today
This topic has been up in the air for a long time. What would be the best approach: get less large boxes or smaller for the same price? What would be pros and cons for every approach for building database layer infrastructure? What would be the best approach to spread write traffic, etc. Let’s think out loud.
First things first so let’s talk about having single box versus few. This is really simple. Having one box for all reads and writes is the simplest architecture possible, but as every simplification it causes some inconveniences. Like outages. Nothing lasts forever and so will not a single box or even cloud instance (they are still utilizing bare metal somehow, right?), which means it will become unavailable at some point so if you used to have just a single box to serve the traffic you will have to wait for recovery or having fun restoring production from backup with downtime and most likely data loss. Not really exciting.
Here comes the second box and so MySQL replication which rise more questions than answers. Since we’re investing money in the second box should it serve live traffic or just be a small backup replica? Well, if master box dies and second is not powerful enough to serve all traffic we can still call it an outage. Not as severe as the one with the single box as we will likely not lose any data, but service is still interrupted which will not make business happy.
What would be the answer? The answer is to have enough capacity in the cluster. if you use two boxes you should have 50% spare capacity which means one completely idle box so in case first will die second will be able to handle full production traffic. Looks like we’ve just spent 50% of infrastructure budget for almost nothing. We can still use stand-by node for backups and to serve some ad-hoc queries, but still doesn’t look efficient, and still vulnerable for a double fault.
Simple math shows us that in the case of 3 boxes we only need 1/3 or 33.3% spare capacity and for four boxes this number is down to 25% which looks way better than half. If you have 10 boxes and one of them dies overall capacity will only drop by 10% so you may not even notice until you’ll get an alert. So what would be the best number? Well, it depends on your MySQL workload types, application requirements and environment you’re in. Cloud environment allows you to fire up instances quickly so you only have to wait for data to be copied to disk from latest backup which turns down turnaround to less than 24 hours (usually). For bare-metal installation, you have to consider delivery time for new boxes so you need to ensure you’ll have enough spare capacity to wait for new boxes to arrive or have the ability to route traffic to another data center. In my experience I would recommend to start with at least three boxes:
- Active master (write traffic)
- Stand-by master (read traffic)
- Backup instance
Having master to serve write traffic and replication-sensitive queries let you utilize stand-by master for read traffic and keep it warm in case of an outage and automatic failover (can be done using MHA, Orchestrator, etc). The backup instance is usually used as delayed replica to prevent data loss in case of human mistake, application bug, etc, and can be scaled down in the cloud environment to keep overall ownership costs low. Three nodes is also a minimal recommended number of nodes for multi-writable MySQL-based technologists like MySQL InnoDB Cluster, MySQL Group Replication, Galera Cluster and XtraDB Cluster.
Next question is how to route traffic from application to DB cluster. There are several ways to do that. One of the approaches is to make the application aware of several hosts and make it to route traffic to different MySQL servers. This will include read-write split on the application side. Issue with this approach it that every time of the server is unavailable or overloaded application instance will be unable to keep working properly unless more or less complicated logic is implemented.
Another approach is to use third-party software to route traffic dynamically based on current cluster status, load, and roles. There is a number of such software available on the market you could find most of them including benchmarks here. Using third party tools giving you the ability to make your application infrastructure unaware and so avoid complicated non-user-oriented logic inside the application, but more importantly change the query routing dynamically without application deployment.
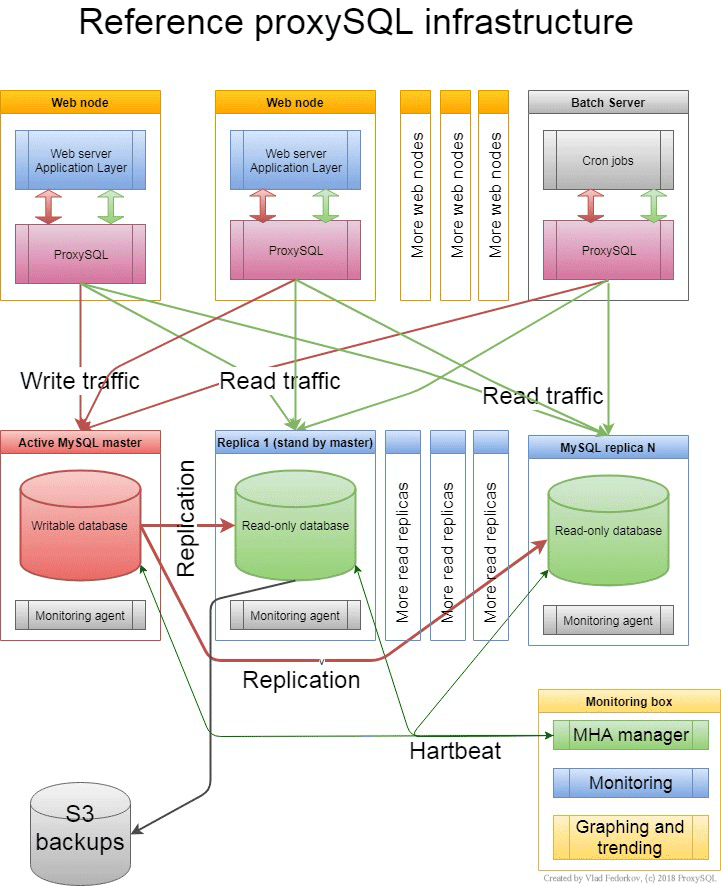
Speaking about routers there are some things which makes ProxySQL a great choice: it supports query level logic and able to understand query itself, user, schema and other details about the traffic. This will allow you to utilize a lot of ProxySQL features like query-based routing, load balancing, failover support, and many more. We usually recommend to setup ProxySQL instances on the application boxes for availability reasons. Typical architecture also includes monitoring host with graphing and failover tools. You can find it below on the infrastructure diagram.
If you have any questions please do not hesitate to contact us. Our performance and scalability experts will help you to analyze your infrastructure and help to build fast and reliable architecture. We also offer long term support and consulting for ProxySQL users.
Authored by: Vlad Fedorkov